
What is a Web Crawl --> A robot program that systematically browse specific webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content. Web crawlers begin crawling a specific set of known pages, then follow hyperlinks from those pages to new pages. Websites that don't wish to be crawled or found by search engines can use tools like the robots.txt file to request bots not index a website or only index portions of it.
FYI....See what the page/site owners are hiding from you, this SEARCHS THE CODE/LINKS. No robots here with hidden agends on what you see and control your thinking.
 |
TRY A CRAWL: Curious on this crawl method, just $24 for 5 URLs (paypal accepted):
|
MY INITIAL CHOICE
While I have the Hadoop setup with HDFS and UBUNTU, the next tool of choice was Nutch for web crawling. There was the initial mistake of choosing Nutch 2.x branch (ie: ver 2.3.1) that has now been largely marked "Inactive" under the project (2.4 seen recently). So, a better choice would have been the older Nutch 1.x stack initially since its simpler and very active. Odd finding with this application/tool buildout, many programmers stuck with the older 1.x tech stack.
At the first steps in learning the tool was looking to go with the latest and greatest version( 2.x vs. 1.x), an incorrect decision and still painfully living with this choice. {No need for the flexible middle teir that the 2.x branch of the tool offers, your cannot actually read the data in Mongo.DB, each record is a big string.}
Key Point - The older 1.x version/branch is a much simpler platform choice with fewer configuration files and is actively being improved.
NEXT GETTING IT INSTALLED AND WORKING
Quite a few trials and errors, it was a two steps forward and one step back kind of thing. I was able to get a single node working with schema files updated. There were THREE key blogs the were key in getting Nutch 2.x all working for me (listed below). Important point, keeping the folder and naming of files consistent is key for success (ls, cat and gedit-cut/past used often - measure twice and cut once approach).
FYI..I now have both branches of the tool working on my machines, on different boxes/distros of course. (also limited updates to working machines)
Some key Nutch Blogs that worked for me:
- Nutch 2.x
- Michael Noll key article {This guy is a god, simple setup and nice detail}
- Nice overview of setup needed {This lady is a tech big picture person, with a good story}
- Another set of steps, Mongodb as backend
- Nutch 1.x
- Medium - Fist Steps on Web Crawler {Quick simple setup and nice detail}
- Nutch WIKI - Basic Steps {Not the greatest, but print and use as punch list}
FYI..I also found that some US Universities technology department gave good student setup help on these tools.
** Strong Suggestion - You need to pick one instructions blog/setup-steps mentioned above and stick to it. I jumped between the three blogs above. So, I have an ongoing issue of a smashed set of steps with files/folders names mixed per author. This open code package was built in batches all sub-modules are version dependent, wikis list these compatible version matrix.
RESULT OF THE CRAWL {after multiple tries, it works - version match is key, not the latest and greatest approach}
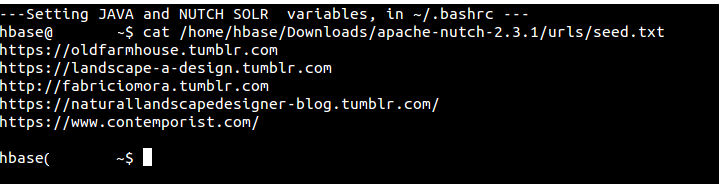
SO, ONCE YOU GET IT ALL WORKING ( Hbase starts, Solr starts) you can begin to crawl. I chose to list 5-6 URLS in the seet.txt file and run three iterations.
Seed File:
URL filter Sample:

Log File Sample:

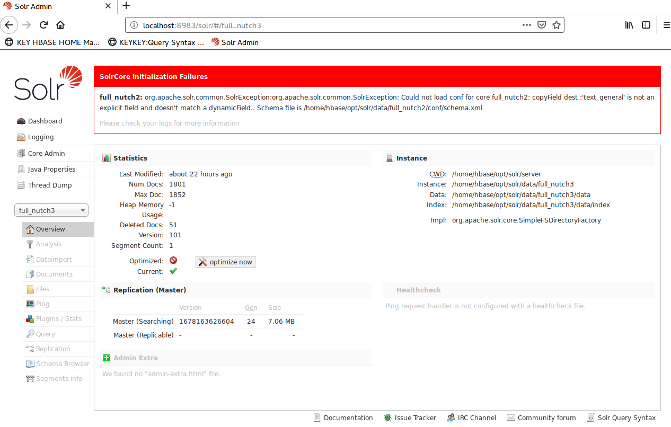
Solr Screen Result:
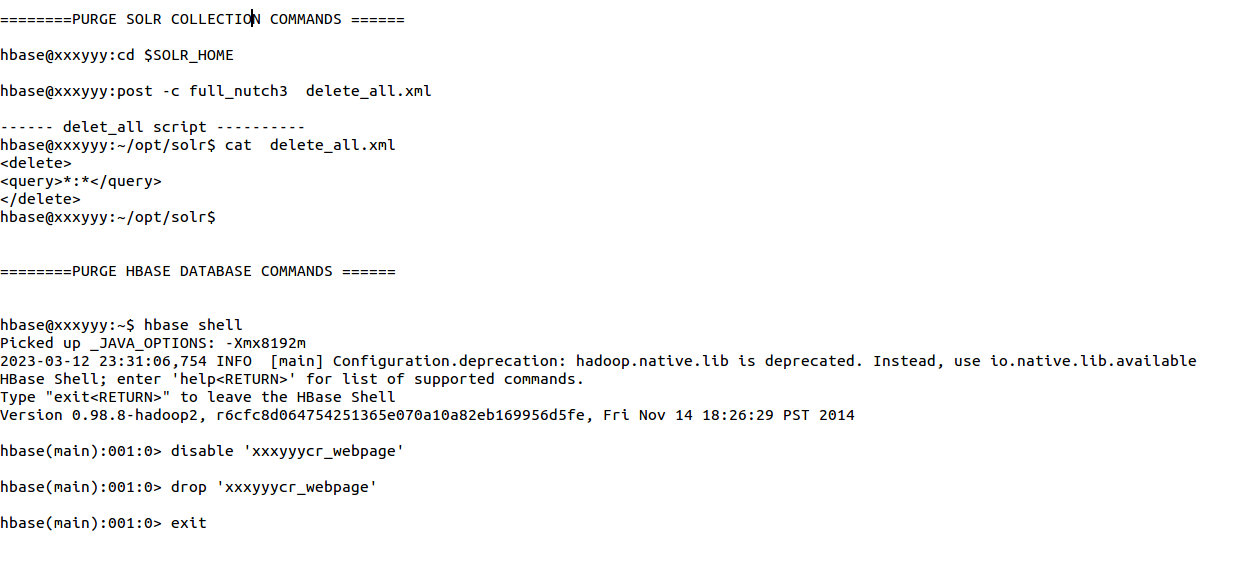
Some Clip Notes: (fyi..house cleaning by erasing past crawls)
I found it very key to erase both the Solr and Crawl detail, then re-run the same crawl. There is a limit in Nutch to not re-crawl the same URLs for a 60-90 day interval. I found the cleaning re-set those restriction and remove any crashed crawls detail.
Latest update - Now working 'ThumbCrawl' request page (link above), 5 URLs for $24.